How to match: to learn or not to learn? (part 2)
Let`s continue to study the nuances of image correspondences finding. Last time we have covered SIFT implementations. Now I`ll show you how to improve the matching part of the process for free (or almost for free).

Recap: local features are detected and local image regions around them are embedded to a vector of floats (SIFT, HardNet, etc). Then L2 aka Euclidean distance between each pair is calculated and the keypoint in the second image, which has the smallest descriptor distance is called a tentative match.

This is the simplest matching strategy, called “nearest neighbor”, or NN. It is so obvious, that I cannot even give a reference, who was first to use it. The obvious drawback is that you do not anyhow evaluate the reliability of the match. Usually, most of the matches are wrong, which impedes geometric verification performance.

To overcome this, one could go for mutual nearest neighbors or cross-consistency check. This means that we do the matching twice: img1->img2 and img2->img1. F1-F2 is kept only if F1 is the nearest neighbor for F2 (img2) and F2 is the nearest neighbor of F1 (img1).


Another way to filter out incorrect matches is first-to-second nearest neighbor ratio check (SNN), proposed by Lowe[1] for SIFTs. Instead of going for the nearest neighbor, we find two and compute the ratio of the distances.
That is an established gold-standard for feature matching in practice, although sometimes being neglected with deep descriptors.
But what if keypoints are detected with multiple orientations or too close to each other? This may lead to violation of the SNN check. To overcome this problem we have proposed[2] in 2015 to look for the second nearest match which is spatially far enough from the 1st nearest. It is called FGINN — 1st geometrically inconsistent nearest neighbor ratio. Implementation is available here.

One step forward, we can do FGINN in both ways: img1 to img2, and img2 to img1. Then an intersection ∩ or union ∪ of tentatives can be kept. The intersection is the mutual NN + FGINN. The union is a simple concatenation of FGINN both ways matches.
These two strategies are not yet published anywhere and are inspired by the symmetric SNN check[3].
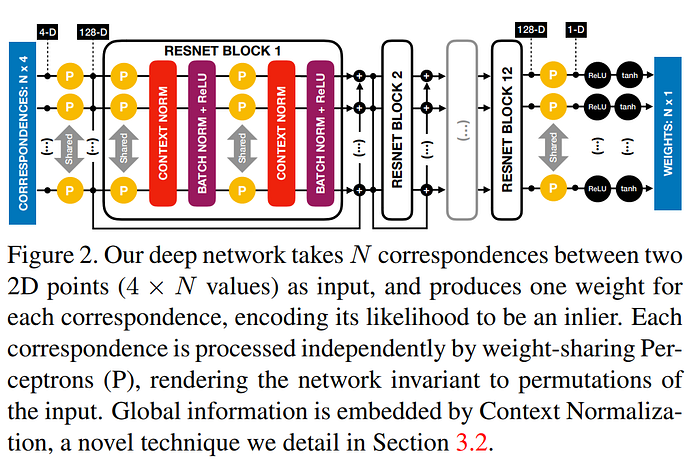
Finally, we can feed the (x,y) coordinates of the correspondences to the deep neural network and let it filter them[4].
All the matching strategies except the learned one, with toy examples are implemented here https://github.com/ducha-aiki/matching-strategies-comparison
So, lets benchmark all the stuff. I thank IMW2019 organizers for giving me access to source code and GT of IMW 2019 benchmark, especially to Eduard Trulls and Kwang Moo Yi for their kind support.
The benchmark is done as following. First, local features are detected, then matched by evaluated strategy and fed into RANSAC to estimate camera pose. The metric is mAP at 15°, which means the number of image pairs, where the precise enough camera pose is recovered.

First, one can see that using the simplest NN or even mutual NN strategies doesn`t work that well.
The SNN ratio gives a huge boost, while the FGINN improves a bit on top of it for all the features. For the SIFT-ContextDesc it even as good, as a learned strategy.
Symmetrical variants of FGINN improve things further, but the gain is not consistent. More powerful and precise descriptors like HardNet, ContextDesc or Superpoint benefit from the union of matches → better recall, while the less robust SIFT needs more precision, which is provided by cross-consistency of intersection FGINN. Yet, the picture could change, depending on how easy image pairs are and how many good matches do we have.
If recall is the problem →go for union, if precision → for intersection.
The only feature from the test, where the learning-based approach is better, is SuperPoint.
Thus, I shamelessly advertise FGINN-based strategies to be used in practice.
That`s all, folks. Stay tuned for the next post in local features series.
[1] Distinctive image features from scale-invariant keypoints. David Lowe. IJCV, 2004
[2]. MODS: Fast and Robust Method for Two-View Matching. D. Mishkin, J. Matas, M. Perdoch, CVIU 2015
[3] Which is Which? Evaluation of local descriptors for image matching in real-world scenarios. Fabio Bellavia and Carlo Colombo, 2019.
[4]. Learning to Find Good Correspondences. Kwang Moo Yi, Eduard Trulls, Yuki Ono, Vincent Lepetit, Mathieu Salzmann, Pascal Fua. CVPR 2018
